How can language models be used
efficiently to scale?
“Language Models are simply models that assign probabilities to a sequence of words or tokens”
Language Models - Some background
For quite some time N-Gram Language models dominated the research field (roughly from 1940-1980) before RNNs followed by LSTMs (around 1990) until the first Neural Language Model in 2003 received more and more hype. Then in 2013 Word2Vec, and 2014 Glove introduced “more Context” to the game. In 2015 the Attention Model became popular and finally in 2017, Transformer, which mainly built on the idea of Attention, ultimately became the de facto standard.
Today Transformers in combination with pre-trained Language Models dominate the research field and deliver groundbreaking results from time to time. Especially, when considering multi-modal modeling – (combination of text, images, videos and speech). Transformer models get most of their generalization power from these pre-trained LMs, meaning their expected quality heavily depends on them.
The technical details of these approaches are clearly out of scope for this post. However, I encourage you to take some time to familiarize yourself with the basic concepts found here.
For us as a company the most important question we try to answer when reviewing new approaches or technologies is not just if the new stuff is better, in some sort of metric or maybe completely. We’ll always try to focus on the “why” (why is there a difference) and what part of the new approach or technology is the reason for this significant difference. Ultimately, we want to pick the right tool for the given task.
The Why
Type |
Key Differentiator |
Explanation |
|---|---|---|
|
Word2Vec
|
Context
|
Context encoded into a vector
|
|
Transformer
|
Self Attention
|
As the model processes each word (each position in the input sequence) self attention allows it to look at other positions in the input sequence for clues that can help lead to a better encoding for this word. |
Concluding the review we were quite surprised to only have spotted two real differentiators, despite the amount of training data they were trained on: Context and Attention.
Efficiency of Language Models
Undeniably, the new kids on the block have some very impressive uplifts in terms of the evaluation metrics. However, the approaches that make use of the Context and Attention concepts, have seen even greater impacts on the computational efficiency of their models, due to the dramatic increase of the amount and complexity of computations.
Granted, business cases conceivably do exist, where the uplift outweighs the computational loss in efficiency, however, none of our customers presented such a case. Even using the most distilled new generation Model we were unable to cut the cost per query to less than 100x times the current cost.
And here are the main reasons why:
Short text. We specialize in search queries. The majority of which are still quite short – 57% of all queries in our dataset are single-word queries, > 72% are two words or less. Therefore, the advantage of contextualized embeddings may be limited.
Low-resource languages. Even shops receiving the majority of their traffic on English domains, typically have smaller shops in low resource languages which also must be handled.
Data sparsity. Search sparsity, coupled with vertical specific jargons and the usual long tail of search queries, makes data-hungry models unlikely to succeed for most shops.
For a Startup like ours, efficiency and customer adoption-rate remain the central aspects when it comes to technical decisions. That’s why we came to the following conclusion:
- For all of our high throughput use-cases, like sequence validation, and Information Entropy optimization, we needed significantly more efficient LMs (than the current state-of-the-art models) that still offer some sort of context and attention.
- For our low throughput use-cases with high potential impact we might use the Transformer based approaches.
Sequence Validation and Information Entropy Optimization
If you work in Information Retrieval (IR) you are aware of what is called “the vocabulary mismatch problem”. Essentially, this means that the queries your users search for are not necessarily contained within your document index. We have covered this problem several times in our blog as it’s by far the most challenging IR topic of which we are aware. In the context of LMs, however, the main question is how they can help reduce “vocabulary mismatch” in a scalable and efficient way.
We structure our stack in such a way that the intent clustering stage already handles things like tokenization, misspellings, token relaxation, word segmentation and morphological transformations. This is where we try to cluster together as candidates, all user queries that essentially have the same meaning or intent. Thereafter, a lot of downstream tasks are executed like the NER-Service, SmartSuggest, Search Insights, etc.
One of the most important aspects of this part of the stack is what we call sequence validation, and information entropy optimization.
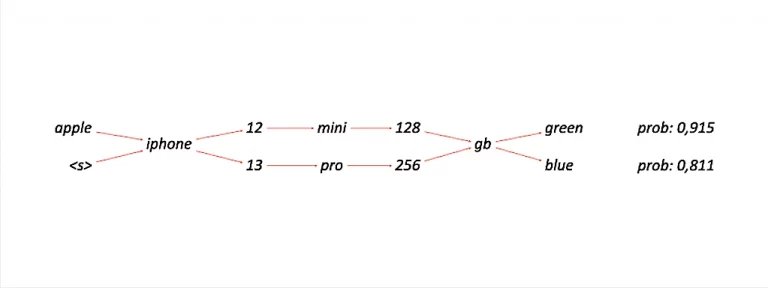
Sequence validation. The main job of our Sequence validation is to assign a likelihood to a given query, phrase or word. Where a sequence with a likelihood of 0 would represent an invalid sequence even if its sub-tokens are valid on their own.Example: While all tokens/words of this query (samsung iphone 21s) might be valid on their own, the whole phrase is definitely not.
Information entropy optimization, however, has a different goal. Imagine you have a bag of queries with the same intent. This set of queries will include some more useful than others. Therefore the job of information entropy optimization is to weight queries containing more useful information higher than queries with less useful information. Example: Imagine a cluster with the following two queries “iphone 13 128” and “apple iphone 13 128gb”. It should be clear that the second query contains much more identifiable information, like the brand and the storage capacity.
Towards an Efficient Language Model for Sequence Validation and Information Entropy Optimization
Coming back to the WHY. During the evaluation we discovered that Context and Attention are the main concepts responsible for the improved metrics between language models. Therefore, we set out to understand in more detail how these concepts have been implemented, and if we might be able to add their conceptual ideas more efficiently, albeit less exactly, to a classical N-Gram Model.
If you are not aware of how N-Gram Language models work, I encourage you to educate yourself here in detail. From a high level, building an N-Gram LM requires parsing a text corpus into equal amounts of tokens (N-Grams) and counting them. These counts are then used to calculate the conditional probabilities of subsequential tokens and/or N-grams. This chaining of conditional probabilities enables you to compute further probabilities for longer token chains like phrases or passages.
Despite the ability of an N-Gram model to use limited context it is, unfortunately, unable to apply the contextual information contained in the tokens, which make up the n-grams, to a larger contextual framework. This limitation led to our first area of focus. We set out to define a way to improve the N-Gram model by being able to add this kind of additional contextual information to it. There are two different approaches to achieve this:
- Increase corpus size or
- Try to extract more information from the given corpus
Increasing the corpus size in an unbiased way is complicated and also less effective computationally. As a result, we tried the second approach by adding one of the core ideas of Word2Vec – the skipGrams – taking into account a larger contextual window. From a computational perspective the main operation for an N-Gram-model is counting tokens or n-Grams. Counting objects is one of the most efficient operations you can think of.
However, trying to get decent results makes it obvious that simply counting the additionally generated skipGrams as is, does not work. We needed to find some sort of weighted counting scheme. The problem of counting these skipGrams in the right way, or more specifically assigning the right weightings, is somehow related to the Attention mechanism in Transformers.
In the end we came up with a pretty radical idea, unsure of whether it would work or not, but the implied boost in computational efficiency and the superior interpretability of the model gave us enough courage to nevertheless try.
Additionally, we should mention that all of our core services are written purely in java. This mainly has efficiency and adoption reasons. We were unable to find any efficient Transformer based native java implementation enabling our use cases. This was another reason for us to try other approaches to solve our use-case rather than just plugging in additional external libraries and technologies.
Introducing the Pruned Weighted Contextual N-Gram Model
The main idea behind the pruned, weighted, contextual N-Gram Model is that we expand the functionality of the model to weight co-occurring n-Grams respective of context and type and, in the final stage, prune the N-Gram’s counts.
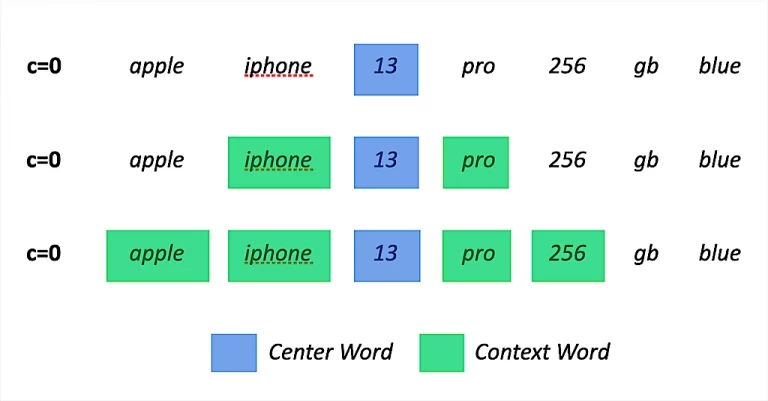
Weighted Contextual N-Gram Counting
To visualize the idea and approach let’s use a typical ecommerce example. Imagine you have a corpus containing the following passage. “bra no wire with cotton cup b 100”.
N-Gram Generation
From here we would create the following unigrams, bigrams and skipGrams. (Where the skipGrams get deduplicated with the bigrams and we’ll use a context window of 5).
|
Set of uniGrams |
[bra, no, wire, with, cotton, cup, b, 100] |
|
Set of biGrams |
[bra no, no wire, wire with, with cotton, cotton cup, cup b, b 100] |
|
Set of skipGrams |
[bra wire, bra with, bra cotton, bra cup, no with, no cotton, no cup, no b, wire cotton, wire cup, wire b, wire 100, with cup, with b, with 100, cotton b, cotton 100, cup 100] |
As you can see by using SkipGrams with a defined context window we dramatically increased the number of usable biGrams for our LM. However when it comes to counting them not all of these bigrams from this passage should be considered with the same relevancy.
Weighted Contextual skipGram Generation
To somehow overcome this issue we introduce what we call contextual proximity weighting. During the skipGram creation we penalize the created skipGrams depending on the positional distance to the current context. An example could be that “bra wire” gets a weight of 0.75 while “bra with” gets 0.4 and “bra cotton” gets 0.2 and so on. (the more positions the skipGram skips the less weight it gets). Now instead of purely counting the occurrences we count occurrences and weights of their positional encodings.
Intermediate Result
By adding this contextual proximity weighting we were able to improve the basic n-Gram Model recall by almost 48% with only a slight 7% decrease in precision.
Conceptual Tokenization
But we wanted to go a step further and encode even more information during this stage. Language contains a lot of logic & structure. For example, in the English language the terms “no/without” and “with” are special terms. Additionally “cup b 100” is a pretty special pattern. A lot of this structure and logic is lost by tokenization most of the time, and modern systems have to learn this sort of structure again from scratch during the training process. So what if we could somehow embed this logic & structure right from the beginning in order to further improve our fine grained weighting depending on context. To verify our intuition we extracted around 100 structural or logical concepts to cope with signal-words, and numerical patterns. We apply these concepts during tokenization and flag detected concepts before they enter the N-Gram generation stage where we finally get: “bra no-wire with-cotton cup-b-100”
|
Set of uniGrams |
[bra, no, wire, no wire, with, cotton, with cotton, cup, b, 100, cup b 100] |
|
Set of biGrams |
[bra no, no wire, wire no wire, no wire with, with cotton, cotton with cotton, with cotton cup, cup b, b 100, 100 cup b 100] |
|
Set of skipGrams |
[bra wire, bra without wire, bra with, bra cotton, without wire, without with, no cotton, no with cotton, wire with, wire cotton, wire with cotton, wire cup, without wire cotton, without wire with cotton, without wire cup, without wire b, with cotton, with cup, with b, with 100, cotton cup, cotton b, cotton 100, cotton cup b 100, with cotton b, with cotton 100, with cotton cup b 100, cup 100, cup cup b 100, b cup b 100] |
From here it’s possible to further manipulate the weighting function we introduced. For example words that follow signal words get less of a weight penalty, while the words with higher positional indexes receive a greater penalty. For subsequent numeric grams, we may consider increasing the weight penalty.
Intermediate Results
By adding the contextual tokenization we were able to further reduce the decrease in precision from 7% to less than 3%. As you may have noticed, we have yet to talk about pruning. With the massive increase in the number of N-Grams to our model, we simultaneously increased the noise. It turns out we almost completely solved this problem, simply by using a simple pruning, based on the combined weighted counts, which is also very efficient in terms of computation. You could, for example, filter out all grams with a combined weighted count of less than 0.8. By adding the pruning we were able to further reduce the decrease in precision to less than 0.2%.
We also have yet to touch the Perplexity metric. Quite a lot of people are convinced that a lower perplexity will lead to better language models — the notion of “better” as measured by perplexity is itself suspect due to the questionable nature of perplexity as a metric in general. It’s important, however, to note that improvements in perplexity don’t always mean improvements in the upstream task, especially when considering small improvements. Big improvements in perplexity, however, should be taken seriously (as a rule of thumb, for language modeling, consider “small” as < 5 and “big” as > 10 points). Our pruned weighted contextual N-Gram model outperformed the standard interpolated Kneser-Ney 3-gram model by 37 points.
Training and Model building
Like many of our other approaches or attempts, this one just seemed way too simple to actually work. This simplicity makes it all the more desirable, not to mention the orders of magnitude better than anything else we could find when it comes to efficiency.
Our largest corpus currently is a German one, comprising over 43-million unique product entries, which contain about 0.5 Billion tokens. After our tokenization, ngram generation, weighted counting and pruning we ended up with 32-million unique grams with assigned probabilities which we store in the model. The whole process takes just a little under 9 minutes using a single-threaded standard Macbook pro, 2,3 GHz 8-Core Intel Core i9, without further optimizations. This means that we are able to add new elements to our corpus, add or edit conceptual tokens and/or change the weighting scheme, and work with an updated model in less than 10 minutes.
Retrieval
Building the LM-Model is just one part of the equation. Efficiently serving the model at scale is just as crucial. Since each of our currently 700-million unique search queries needs to be regularly piped through the LMs, the retrieval performance and efficiency are crucial for our business too. Due to very fast build times of the model we decided to index the LM for fast retrieval in a succinct, immutable data-structure using minimal perfect hashing for storing all the grams and their corresponding probabilities. Perfect hash is a hash which guarantees no collisions. Without collisions it’s possible to store only values (count frequencies) and not the original n-grams. Also we can use a nonlinear quantization to pack the probabilities into some lower bit representation. This does not affect the final metrics but greatly reduces memory usage.
The indexation takes around 2 minutes with the model using just a little bit more than 500mb in memory. There is still significant potential to further reduce memory footprint. For now though, we are more than happy with the memory consumption and are not looking to go the route of premature optimization.
In terms of retrieval times the Minimal Perfect Hash data structure which offers O(1) is just incredible. Even though we need several queries against the data structure to value a given phrase we can serve over 20.000 concurrent queries single-threaded on a single standard Macbook pro 2,3 GHz 8-Core Intel Core i9.
Results
All models including the 3-gram Kneser-Ney model are trained on the same corpus, a sample of our german corpus containing 50-million words for comparison. We tried BERT with the provided pretrained models but the quality was not comparable at all. Therefore we trained it from scratch in order to get a fair comparison.
Model |
Accuracy |
PPL |
Trained On |
Memory Usage |
Training Time |
95% / req time |
Efficiency |
|---|---|---|---|---|---|---|---|
|
Kneser-Ney-3-Gram |
62.3% |
163.0 |
CPU |
385 mb |
7 min |
0.34 ms |
47-Watt |
|
Transformer
|
75.8% |
110.5 |
CPU |
3.7 gb |
172 min |
4.87 ms |
3.6-kWatt |
|
pruned weighted contextual 3-Gram Kneser-Ney |
91.2% |
125.7 |
CPU |
498 mb |
9 min |
0.0023 ms |
60-Watt |
|
|
+20% |
-12% |
|
-87% |
-95% |
-99% |
-98% |
In summary we are very pleased with the results and achieved all our goals. We dramatically increased the computational efficiency whilst still not losing much in terms of quality metrics and maintaining maximum compatibility with our current tech stack.
What's next…?
First of all we are working on documenting and open-sourcing our pruned weighted contextual N-Gram model together with some freely available corpus under our searchHub github account.
For now our proposed LM lacks one important aspect compared to current state of the art models in terms of the vocabulary mismatch problem – word semantics. While most neural models are able to capture some sort of semantics our model is not directly able to expose this type of inference in order to, for example, also properly weight synonymous tokens/terms. We are still in the process of sketching potential solutions to close this gap whilst maintaining our superior computational efficiency.