The importance of Synonyms
in eCommerce Search
Almost any person working with search is somehow aware of Synonyms and their importance when optimizing search to improve recall. Therefore, it will be no surprise to say that adding synonyms is one of the most essential methods of introducing domain-specific knowledge into any symbolic-based search engine.
"Synonyms give you the opportunity to tune search results without having to make major changes to your underlying data and help you to close the vocabulary gap between search queries and product data."
To better underline the use-cases and importance, please consider the following eCommerce examples:
If a customer searches for “laptop,” but the wording you are using in your product data is “notebook,” you need a common synonym, or you won’t make the sale. More precisely, this is a bidirectional synonym-mapping which means that both terms have an equivalent meaning.
If a customer is looking for “accu drill” or “accumulator screwdriver,” you’ll end up setting up several bidirectional synonym-mappings, one for accu = accumulator and another one for drill = screwdriver.
If a customer searches for “trousers,” you might also want to show him “jeans,” “shorts,” and “leggings.” These relationships are particular types of synonyms, so-called Hyponyms. The most intuitive definition I’m aware of for a hyponym is the “directed-typeOf” definition. So every jeans, shorts or leggings is a “typeOf” trouser but not the other way around.
We use synonyms to tell the search system to expand the search space (synonym-expansion). Or in other words, if a search query contains a synonym, we ask the search engine to also search for other synonymous words/phrases in the background.
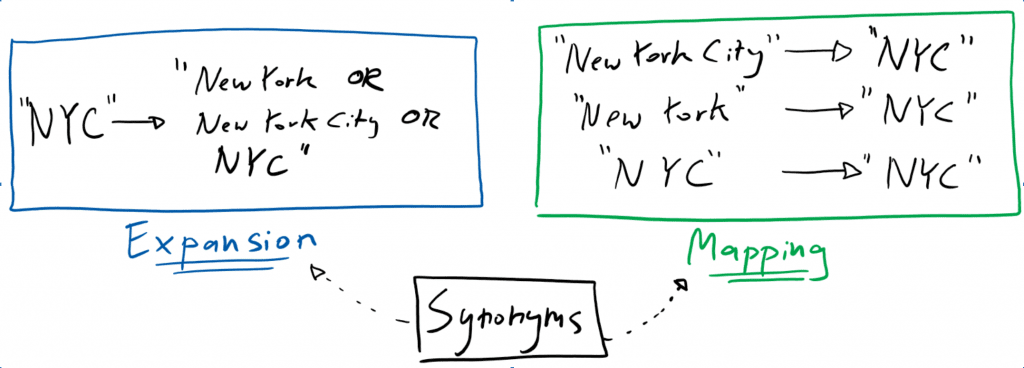
All of the above cases are very common and sound pretty straightforward. But the internal dependencies on other parts of the search analysis chain and the fundamental context-dependent meaning of words are often hidden away and not evident to the people trying to solve specific problems by introducing or managing synonyms. This often leads to unexpected, sometimes even unwanted, results.
Spaghetti-Synonyms best of
1. Synonyms with dependency on proper spelling and tokenization
For most search engines, the quality of the synonym expansion is highly dependent on the quality of the so-called tokenization. So, for example, if we consider search phrases like “sonylaptopcharger”; “sony laptopcharger”; “sony laptopchager” or “charger for sonylaptop,” a simple synonym-expansion with “notebook” will most likely not work as expected. That’s because the tokenization process is unable to produce a token “laptop” that could be expanded with “notebook.”
Additional logic and manual effort are needed to cover these cases. Unfortunately, that’s usually the point at which users start to flood the synonym files by adding misspellings and decompositions. But this is obviously not a scalable, long-term solution to the problem.
2. Transitive compounding effects of synonyms
Since there might be hundreds or even thousands of synonyms you’d need to cover, you will most probably end up with a long list of synonyms defining some terms and their specified mappings (“expansion candidates”).
Now imagine you have the following two entries:
dress, attire, apparel, skirt, costume
shoes, boots, footgear
Maybe you have added these synonym mappings at different times to improve the recall for a specific query like “dress” or “shoes,” for example. For these queries in isolation, everything seems fine. However, you may have unintentionally opened Pandora’s box from the moment you added the second entry. From now on, it’s likely that searches for “dress shoes” will no longer deliver the expected results. Furthermore, depending on the query parsing used, these results will be inflated by irrelevant matchings of all sorts of dresses and shoes.
Again the most common way to solve this problem is to add manual rules like preprocessors or filters to remove the unwanted matches from the result.

2. Transitive compounding effects of synonyms
To be clear, taking the semantic context into account is the single greatest challenge for synonyms. Depending on the context, a word can have different meanings in all natural languages. For example, the word “tee” is often used as a synonym for “t-shirt” in the context of fashion, while “tee” has an entirely different meaning in the context of “food.”
“When your customers are formulating a query they take a specific semantic context for granted. The applied synonym expansion needs to capture this context to give the best results.”
Let’s say you work for an electronics shop and came up with the following well-thought-through list of synonyms to increase recall for searches related to the concept of “iphone cases.”
iphone case, iphone backcover, apple backcover, apple smartphone case
You check a couple of queries, and it seems like the job is done. Well, until someone types in the query “ipad apple backcover” and gets flooded by numerous irrelevant iPhone covers. That’s because the synonym expansion does not consider the context around the synonyms.
BTW: do you still remember the example “accu drill” or “accumulator screwdriver” from the beginning? Hopefully, you spotted the point where I might have tricked you. While accu and accumulator are accurate synonyms, drill and screwdriver are context-dependent synonyms.
We have seen these kinds of challenges pop up with every eCommerce retailer. Even the most advanced retailers have struggled with the side-effects of synonyms in combination with (stopwords, acronyms, misspellings, lemmatization, and contextual relationships).
At searchhub, we thrive on making it easier to manage and operate search engines while helping search engines better understand search queries. That’s why we decided to tackle the problem of synonyms as well.
Introducing searchhub concepts
The main idea behind searchhub is to decouple the infinite search-query-space from the relatively small product-catalog-space. As a search user, the number of words, meanings, and ways to formulate the same intent are much much higher than the number of words you have available in your product catalog and, therefore, in your index. This challenge is called the “language gap.”
We meet this query intent challenge head-on by clustering the search-query-space. The main advantage of taking this approach is the sheer volume of information gathered from several, sometimes thousands of queries inside a single cluster, which allows us to add information and context to every query naturally. Not only that, this enriched query context provided us with the necessary foundation to design a unique solution (so-called “concepts”) to solve the challenges of transitive compound synonyms, naturally handling contextual synonyms, and removing dependencies on spelling and tokenization.
Let’s take a very typical example from the electronics world where we would like to encode the contextual semantic relationship between the following terms:
”two door fridge” and “side by side”
This is a pretty challenging relationship because we try to encode “two door” and “side by side” as equivalent expressions but only in the context of the query intent fridge. That’s why the search manager intelligently added the word fridge, as many other products might have two doors and not be side by side.
But maybe the search manager was unaware of the brand called “side by side,” and that next week the shop will also list some fantastic side-by-side freezers which are not precisely fridges 🙂
In searchhub, however, you could easily add such an underlying relationship (we call it concept-definition) by simply defining “two door” = “side by side.” Under the hood, searchhub takes care of morphology, spelling, tokenization, contextual dependencies and only applies the concepts (synonyms) if the query intent is the same.
But not only that. Since every query in our clusters is equipped with performance KPIs, we naturally support performance-dependent weighted synonyms if your search platform supports them.
We tested this solution intensely with some of our beta customers, and the results and feedback have been overwhelming. For example
We reduced the number of synonyms previously managed in the search platform for our customers, on average, by over 65%. At the same time, we increased query synonym expansion coverage by 19% and precision by more than 14%.
This means we found a very scalable, and more importantly fully transparent, way for our customers to manage and optimize their synonyms at scale.
BTW searchhub also learns these kinds of concept-definitions automatically and proactively recommends them so you can concentrate on validation rather than generation.
If you are interested in optimizing your synonym handling, making it more scalable and accurate, let’s talk……..
Under the hood - for our technical audience
Synonyms are pretty easy to add in quite a lot of cases. Unfortunately, only a few people understand the challenges behind correctly supporting synonyms. Proper synonym handling is no easy task, especially for multi-word expressions, which introduce a lot of additional complexity.
We decided to use a staged approach consisting of two stages to tackle this challenge with our concepts method.
Stage 1 - Query Intent Clustering
Before we have a deeper look at the solution, let’s define some general conditions to consider:
- By using query-clusters where morphology, spelling, tokenization, and contextual dependencies like (dresses for women, drill without accu, sleeveless dress) are already taken into account, we can finally ignore spelling, tokenization and structural semantics’ dependencies.
- We also no longer have to account for language specifics since this is already handled by the query clustering process (for example, a “boot” can mean a shoe or a boat in german, while in English, it can mean shoe or trunk).
Stage 2 - Concepts, a way to encode contextual equivalent meaning of words or phrases
Once a concept is defined, searchub begins with a beautifully simple and efficient concept matching approach.
- We scan all clusters and search for those affected by one or more concept definitions. This is a well-known and easy to solve IR problem even at a large scale.
- We reduce all concept-definitions for all concept-candidates using so-called concept-tokens (for example
<concept-ID>). This is necessary as several transitive concept-definitions may exist for a single concept-object in multiple languages. - Aggregate all reduced candidates, evaluate them based on their semantic context, and treat only the ones as conceptually equivalent, which share the same semantic context. This stage is essential, so it needs the most attention. You don’t want
<concept-1>grillandgrill<concept-1>to be equivalent even though they contain the same tokens or words. - The last step is to merge all conceptually equivalent candidates/clusters provided they represent the same query intent. This might seem counter-intuitive since we usually think of synonym expansion. Still, to expand the meaning of a query-intent-cluster, we have to add information by merging it into the cluster.
As a search expert, this approach might look way too simple to you, but it has already proved bullet-proof at scale. And since our searchhub platform is designed as a lambda architecture, this is all done asynchronously, not even affecting search query response times.
credit feature image: Diego Garea Rey | www.diegogarea.com