You may think the word “dumb services” in connection with software orchestration in the title is clickbait. However, I can assure you, the aforementioned “Orchestration with Dumb Services”, is a real and simple software orchestration concept certainly to improve your sleep.
Any engineer, DevOps, or software architect can relate to the stress of running a loaded production system. To do so well, it’s necessary to automate, provision, monitor, provide redundancy and fail-over to hit those SLAs. The following paragraphs cut to the chase. You won’t see any fancy buzzwords. I aim to help avoid pitfalls into which many companies stumble, when untangling monolithic software projects. Or, for that matter, even when building small projects from scratch. While the concept is not applicable for every use case, it does fit perfectly into the world of e-commerce search. It’s even applicable for full-text search. Generally, wherever the search index read and writes are separate pipelines, this is for you! So, what are we waiting for? Let’s start orchestrating with dumb services.
What is the Difference Between Regular vs. Dumb services
To begin, let’s define the term “service”
A service is a piece of software that performs a distinct action.
Nowadays, a container running as part of a kubernetes cluster is a good example of a service. This container can spin-up multiple instances of the service to meet demand. The configuration of a so-called regular service points it to other services it may need. These could be things like connections to databases, and so on.
Regular Services in action are seen illustrated in the diagram to the right. As they grow, companies run many such hierarchically organized services.
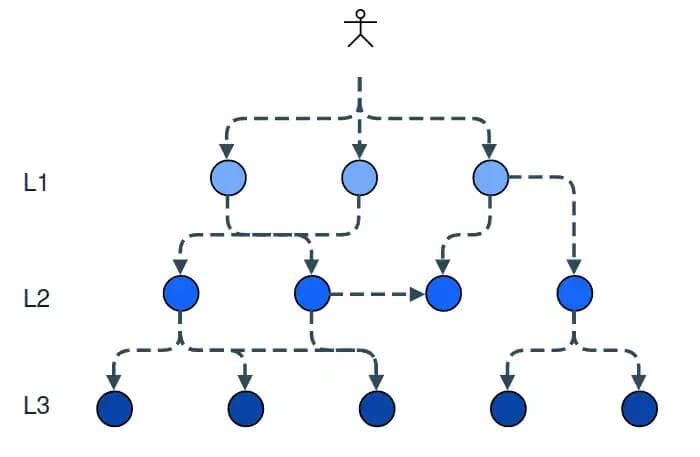
Regular Service Hierarchy
Dumb Services
Now, let’s clarify what “dumb service” means. In this context, a dumb service is a service which knows nothing about its environment. Its configuration is reduced to performance related aspects (ex. memory limits). When you start such a service, it does nothing — no connection to other services, no joining of clusters, just waits to be told what to do.
Orchestrator Services
To create a full system composed of dumb services, you deploy another service type called an “orchestrator”. The orchestrator is the “brain”, the dumb services are the “muscle” — the brain tells the muscles what to do.
The orchestrator sends tasks to each service. Additionally, it directs the data exchange between services. Finally, it pushes data and configurations to the client facing services. Furthermore, the orchestrator initiates all service state changes.
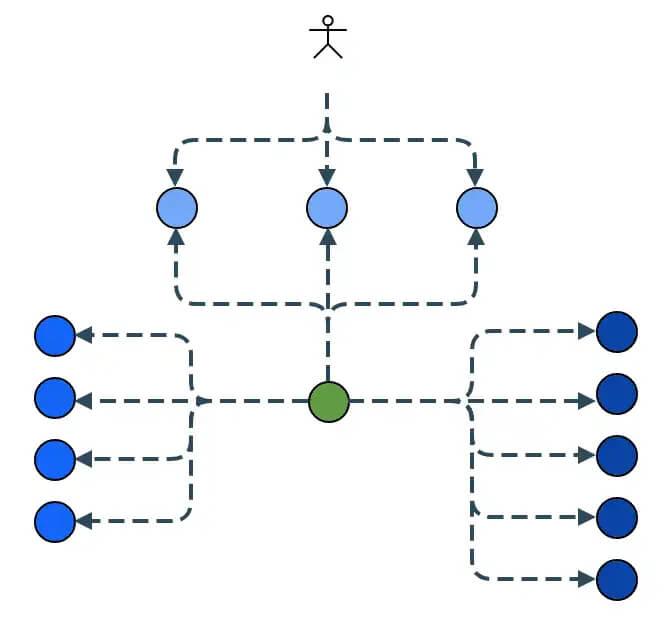
Dumb Service Orchestration
Let’s review our “regular vs. dumb” services in light of two key aspects of a software system — fault tolerance and scalability.
Fault Tolerance
Fault Tolerance with Regular Services
In the regular case diagram we illustrate a typical flow during a user request. The client facing services at level 1 (labeled with L1 in the diagram) need to call the internal services at levels 2 and 3 to complete the request. Naturally, in a larger system, this call hierarchy goes much deeper. To meet the SLA, all services must be up all time as any incoming request could call a service further down the hierarchy. This is obviously a hard task, combining N services with uptime of 99.95% does not result in 99.95% for the entire system — in the worst case, for a request that hits 5 services you’d go down to 99.7% (99.95 to the power of N).
Fault Tolerance with dumb services.
Let’s compare this to the system composed of dumb services. The client facing services on level 1, serve the request without any dependency to the services at level 2 and 3. We only need to ensure the SLA of the L1 services to ensure the SLA of the entire client facing part of the system — services at levels 2 and 3 could go down without affecting user requests.
Scaleability
Scaling Regular Services
Scaling the system composed of regular services, necessarily means scaling the entire system. If only one layer is scaled, it could result in overloading the lower layers of the system as user requests increase. The process of scaling also means more automation as you need to correctly wire the services together to scale.
Scaling Dumb Services Architecture
Let’s take a look again at our dumb services architecture. Each service can be scaled independently as it has no direct dependencies on any other services. You can spin up as many client facing services as you like to meet increased user requests without scaling any of the internal systems. And vice versa, you can increase the number of nodes for internal services on demand to meet a heavy indexing task and then easily spin it down. Again, all this without affecting user requests.
What about Testing?
Finally, testing your service is simple: you start it and pass a task to it — no dependencies you need to consider.
Wrapping it up
In conclusion, you can simplify your architecture significantly by deploying this simple concept. However, as mentioned previously, this does not apply to all use cases. Situations, where your client facing nodes are part of both the reading and writing data pipelines, are harder to organize in this way. Even still, any time you’re faced with designing a system composed of multiple services, think about these patterns — it may save you a few sleepless nights.