In my first post, I talked about the importance of site search analytics for e-commerce optimization. In this follow-up, I would like to show one way how to easily build a site search analytics system at scale, without spending much time and effort on answering these ever present questions:
- Which database is best for analytics?
- How do I operate that database at scale?
- What are the operating costs for the database?
How-To Site-Search Analytics without the Headache
These questions are important and necessary. Thankfully, in the age of cloud computing, others have already thought about, and found solutions to abstract out the complexity. One of them is Amazon Athena. This will help us build a powerful analysis tool from, in the simplest case, things like CSV files. Amazon Athena, explained in its own words:
Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. Amazon Athena
This introductory sentence from the Amazon website already answers our questions 1 and 2. All that remains is to answer question 3: how much does it cost? This is answered quickly enough:
- $5.00 per TB of data scanned by Athena
- Standard AWS S3 rates for storage, requests, and data transfer
AWS offers a calculator to roughly estimate the cost. Because Amazon Athena uses Presto under the hood, it works with a variety of data formats. This includes CSV, JSON, ORC, Apache Parquet, and Apache Avro. Choosing the right file format can save you up to a third of the cost.
No data, no DIY analytics
A site search analytics tool requires a foundation. Either data from an e-commerce system or any site search tracking tool like the searchhub search-collector will suffice. For now, we will focus on how to convert data into the best possible format, and leave the question of “how to extract data from the various systems” for a separate post.
As the database needn’t scan a complete row but only the columns which are referenced in the SQL query, a columnar data format is preferred to achieve optimal read performance. And to reduce overall size, the file format should also support data compression algorithms. In the case of Athena, this means we can choose between ORC, Apache Parquet, and Apache Avro. The company bryteflow provides a good comparison of these three formats here. These file formats are efficient and intelligent. Nevertheless, they lack the ability to easily inspect the data in a humanly readable way. For this reason, consider adding an intermediate file format to your ETL pipeline. Use this file to store the original data in an easy-to-read format like CSV or JSON. This will make your life easier when debugging any strange-looking query results.
What are we going to build?
We’ll now build a minimal Spring Boot web application that is capable of the following:
- Creating dummy data in a humanly readable way
- Converting that data into Apache Parquet
- Uploading the Parquet files to AWS S3
- Query the data from AWS Athena using JOOQ for creating type-safe SQL queries using the Athena JDBC driver.
Creating the application skeleton
Head over to Spring initializr and generate a new application with the following dependencies:
- Spring Boot DevTools
- Lombok
- Spring Web
- JOOQ Access Layer
- Spring Configuration Processor
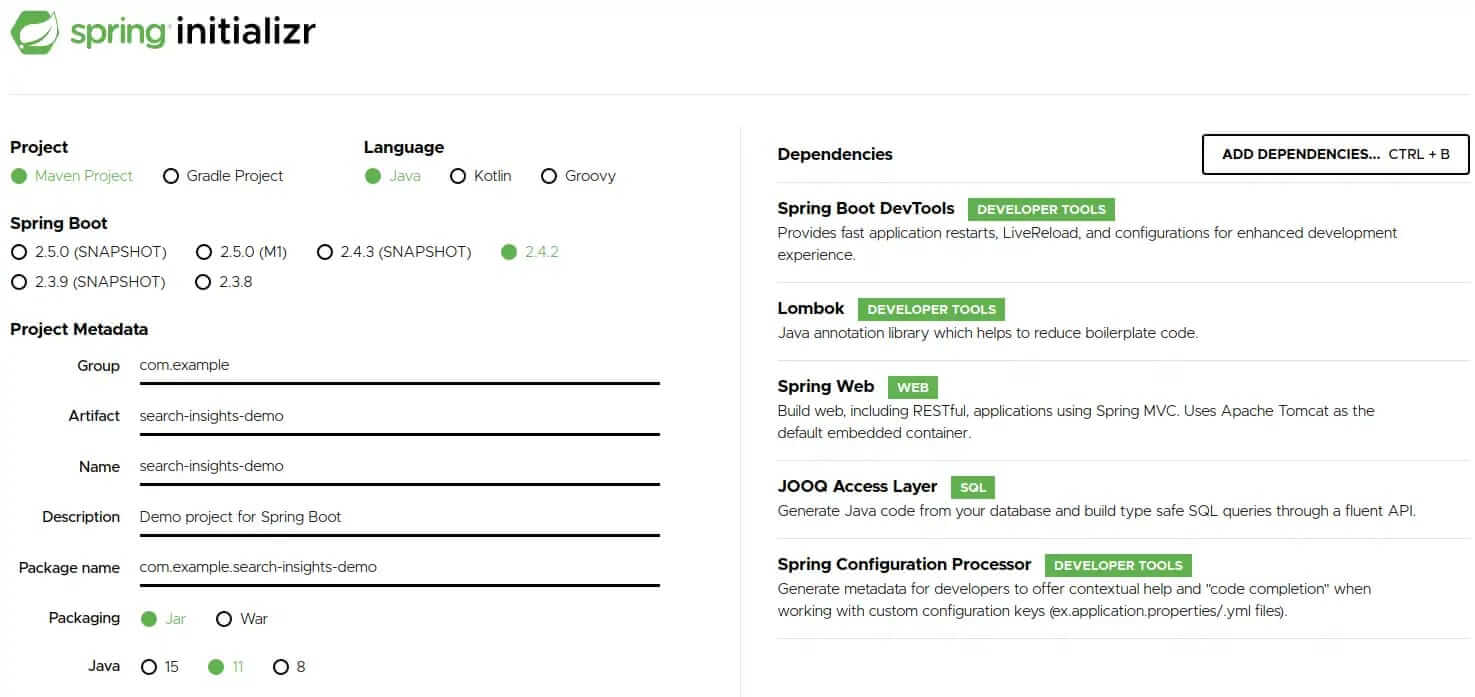
Hit the generate button to download the project. Afterward, you need to extract the zip file and import the maven project into your favorite IDE.
Our minimal database table will have the following columns:
- query
- searches
- clicks
- transactions
We will use the jooq-codegen-maven plugin, to build type-safe queries with JOOQ, which will generate the necessary code for us. The plugin can be configured to generate code based on SQL DDL commands. Create a file called jooq.sql inside src/main/resources/db and add the following content to it:
CREATE TABLE analytics (
query VARCHAR,
searches INT ,
clicks INT,
transactions INT,
dt VARCHAR
);
Next, add the plugin to the existing build/plugins section of our projects pom.xml:
<plugin>
<groupId>org.jooq</groupId>
<artifactId>jooq-codegen-maven</artifactId>
<executions>
<execution>
<id>generate-jooq-sources</id>
<phase>generate-sources</phase>
<goals>
<goal>generate</goal>
</goals>
<configuration>
<generator>
<generate>
<pojos>true</pojos>
<pojosEqualsAndHashCode>true</pojosEqualsAndHashCode>
<javaTimeTypes>true</javaTimeTypes>
</generate>
<database>
<name>org.jooq.meta.extensions.ddl.DDLDatabase</name>
<inputCatalog></inputCatalog>
<inputSchema>PUBLIC</inputSchema>
<outputSchemaToDefault>true</outputSchemaToDefault>
<outputCatalogToDefault>true</outputCatalogToDefault>
<properties>
<property>
<key>sort</key>
<value>semantic</value>
</property>
<property>
<key>scripts</key>
<value>src/main/resources/db/jooq.sql</value>
</property>
</properties>
</database>
<target>
<clean>true</clean>
<packageName>com.example.searchinsightsdemo.db</packageName>
<directory>target/generated-sources/jooq</directory>
</target>
</generator>
</configuration>
</execution>
</executions>
<dependencies>
<dependency>
<groupId>org.jooq</groupId>
<artifactId>jooq-meta-extensions</artifactId>
<version>${jooq.version}</version>
</dependency>
</dependencies>
</plugin>
The IDE may require the maven project to be updated before it can be recompiled. Once done, you should be able to see the generated code under target/generated-sources/jooq.
Before creating SQL queries with JOOQ, we first need to create a DSL-context using an SQL connection to AWS Athena. This assumes we have a corresponding Athena JDBC driver on our classpath. Unfortunately, maven central provides only an older version (2.0.2) of the driver, which isn’t an issue for our demo. For production, however, you should use the most recent version from the AWS website. Once finished, publish it to your maven repository. Or add it as an external library to your project, if you don’t have a repository. Now, we need to add the following dependency to our pom.xml:
<dependency>
<groupId>com.syncron.amazonaws</groupId>
<artifactId>simba-athena-jdbc-driver</artifactId>
<version>2.0.2</version>
</dependency>
Under src/main/resources rename the file application.properties to application.yml and paste the following content into it:
spring:
datasource:
url: jdbc:awsathena://<REGION>.amazonaws.com:443;S3OutputLocation=s3://athena-demo-qr;Schema=demo
username: ${ATHENA_USER}
password: ${ATHENA_SECRET}
driver-class-name: com.simba.athena.jdbc.Driver
This will auto-configure a JDC connection to Athena and Spring will provide us a DSLContext bean which we can auto-wire into our service class. Please note that I assume you have an AWS IAM user that has access to S3 and Athena. Do not store sensitive credentials in the configuration file, rather pass them as environment variables to your application. You can easily do this, if working with Spring Toll Suite. Simply select the demo application from the Boot Dashboard; then the pen icon to open the launch configuration; navigate to the Environment tab and add the following entries:
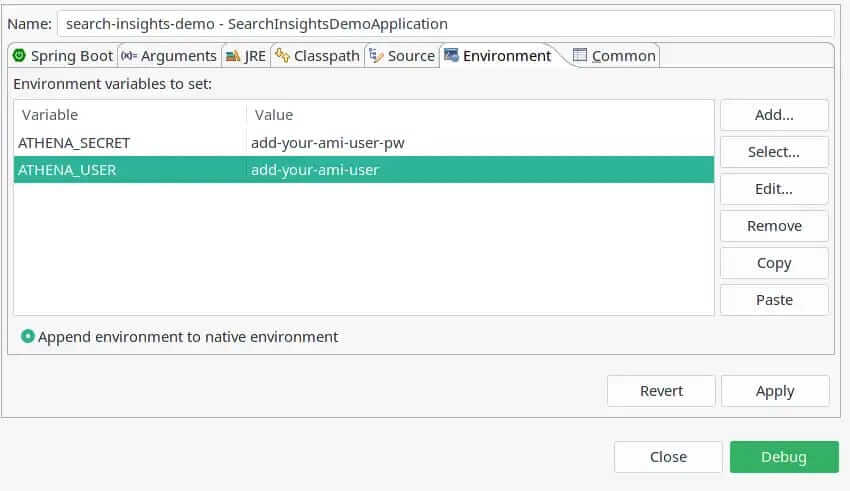
Please note the datasource URL property, where you need to add proper values for the following placeholders directly in your properties.yml:
- REGION: The region you created your Athena database in. We will cover this step shortly.
- S3OutputLocation: The bucket where Athena will store query results.
- Schema: The name of the Athena database we are going to create shortly.
We are about to load our Spring Boot application. Our Athena database is still missing, however. And the application won’t start without it.
Creating the Athena database
Login to the AWS console and navigate to the S3 service. Hit the Create bucket button and choose a name for it. You won’t be able to use the same bucket as in this tutorial because S3 bucket names must be unique. However, the concept should be clear. For this tutorial, we will use the name, search-insights-demo and skip any further configuration. This is the location to where we will, later, upload our analytics files. Press Create bucket, and navigate over to the Athena service.
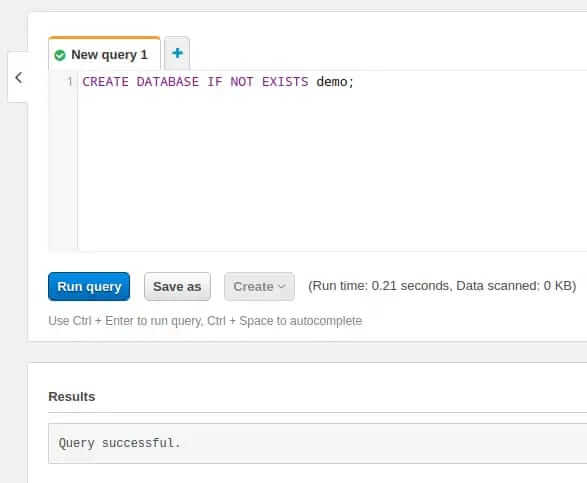
Paste the following SQL command into the New query 1 tab:
CREATE DATABASE IF NOT EXISTS demo;
Hit Run query. The result should look similar to this:
Now, that we have successfully created a database open the Database drop-down on the left-hand side and select it. Next we create a table by running the following query:
CREATE EXTERNAL TABLE IF NOT EXISTS analytics (
query STRING,
searches INT ,
clicks INT,
transactions INT
)
PARTITIONED BY (dt string)
STORED AS PARQUET
LOCATION 's3://search-insights-demo/'
The result should look similar to this:
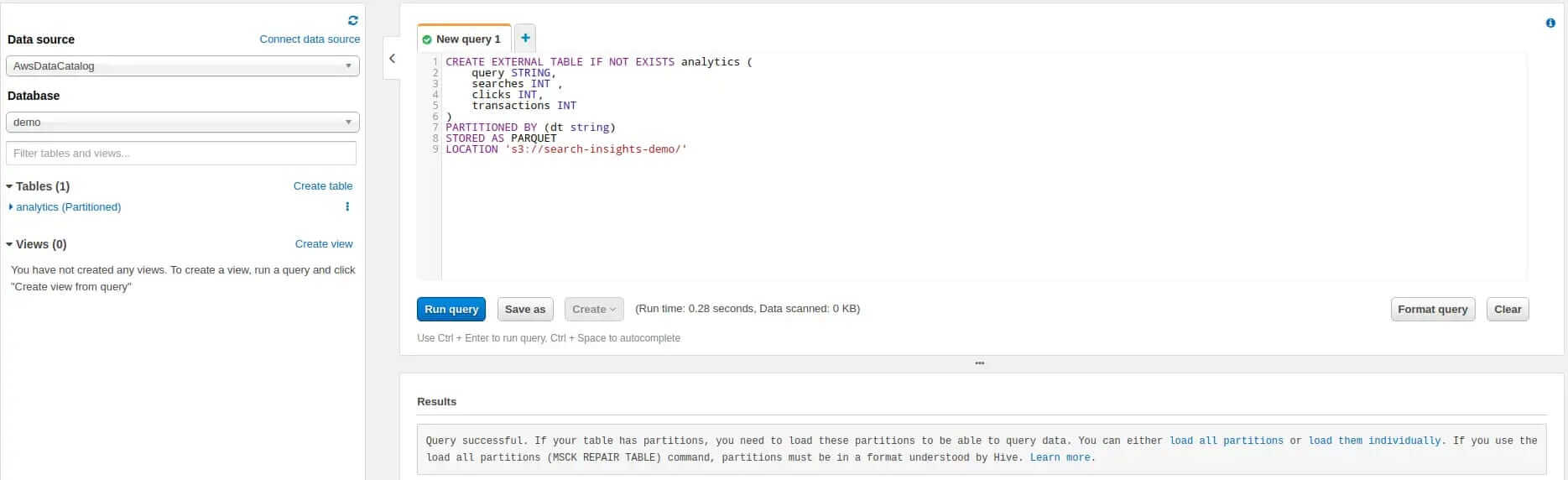
Please note some important details here:
- We partition our table by a string called dt. By partitioning, we can restrict the amount of data scanned by each query. This improves performance and reduces cost. Analytics data can be partitioned perfectly into daily slices.
- We state that our stored files are in Apache Parquet format.
- We point the table to the previously created S3 bucket. Please adjust the name to the one you have chosen. Important: the location must end with a slash otherwise you will face an IllegalArgumentException.
Adding the first query to our application
Now, that everything is setup we can add a REST controller to our application that counts all records in our table. Naturally, the result we expect is 0 as we have yet to upload any data. But this is enough to prove that everything is working.
Now, return to the IDE and, in the package com.example.searchinsightsdemo.service, create a new class called AthenaQueryService and paste the following code into it:
package com.example.searchinsightsdemo.service;
import static com.example.searchinsightsdemo.db.tables.Analytics.ANALYTICS;
import org.jooq.DSLContext;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class AthenaQueryService {
@Autowired
private DSLContext context;
public int getCount() {
return context.fetchCount(ANALYTICS);
}
}
Note that we auto-wire the DSLContext which Spring Boot has already auto-configured based on our settings in the properties.yml. The service contains one single method that uses the context to execute a fetch count query on the ANALYTICS table, which the JOOQ code generator has already created (see the static import).
A Spring service is nothing without a controller exposing it to the outside world, so let’s create a new class, in the package com.example.searchinsightsdemo.rest, called AthenaQueryController. Go there now and add the following:
@RestController
@RequestMapping("/insights")
public class AthenaQueryController {
@Autowired
private AthenaQueryService queryService;
@GetMapping("/count")
public ResponseEntity<Integer> getCount() {
return ResponseEntity.ok(queryService.getCount());
}
}
Nothing special here. Just some Spring magic that exposes the REST endpoint /insights/count. This in turn calls our service method and returns the results as a ResponseEntity.
We need to add one more configuration block to the properties.yml, before launching the application for the first time:
logging:
level:
org.jooq: DEBUG
This will enable debug logging for JOOQ which enables viewing the SQL queries it generates as plain text in our IDE’s console.
That was quite a piece of work. Fingers crossed that the application boots. Give it a try by selecting it in the Boot Dashboard and pressing the run button. If everything works as expected you should be able to curl the REST endpoint via:
curl -s localhost:8080/insights/count
The response should match the expected value of 0, and you should be able to see the following log message in your console:
Executing query : select count(*) from "ANALYTICS"
Fetched result : +-----+
: |count|
: +-----+
: | 0|
: +-----+
Fetched row(s) : 1
Summary
In this first part of our series, we introduced AWS Athena as a cost-effective way of creating an analytics application. We illustrated how to build this yourself by using a Spring Boot web application and JOOQ for type-safe SQL queries. The application hasn’t any analytics capabilities so far. This will be added in part two where we create fake data for the database. To achieve this, we will first show how to create Apache Parquet files; partition them by date, and upload them via AWS S3 Java SDK. Once uploaded, we will look at how to inform Athena about new data.
Stay tuned and come back soon!
The source code for part one can be found on GitHub.